
VMware Site Recovery Manager (SRM) - Parte 3
Design e configurazione di Inventory Mappings, Placeholder VM e Array-Based Replication
Pascal Carone
6/10/20257 min read


Indice
Introduzione
Inventory Mappings: compute, folder, network, policy, subnet, reverse e limitazioni
Placeholder VM e Placeholder Datastore: requisiti tecnici e ruolo nel recovery
Array-Based Replication in SRM: SRA, Array Pairs, Datastore Groups e Consistency Group
Conclusione
Introduzione
Per garantire un failover affidabile in caso di disastro, SRM richiede una preparazione accurata degli oggetti logici nel sito protetto e in quello di recovery. In particolare, occorre configurare gli inventory mappings che associano reti, risorse di calcolo, cartelle e policy storage tra i due siti, e definire placeholder (VM e datastore) che riservano spazio nel sito di recovery. Senza questi mapping SRM non riesce a “tradurre” correttamente le risorse tra siti e il processo di ripristino può fallire o richiedere interventi manuali. Inoltre, la replica a livello di storage deve essere progettata in modo coerente con l’architettura SRM (ad es. gruppi di consistenza in linea con i datastore group calcolati da SRM) per evitare problemi durante il failover. In questo articolo esploriamo nel dettaglio ciascun aspetto di design e configurazione, per fornire una guida completa all’implementazione di SRM.
Inventory Mappings
Gli inventory mapping definiscono quali risorse del sito di recovery devono essere usate per le VM dopo il failover. In pratica SRM utilizza i mapping per sapere, ad esempio, in quale cluster o host avviare la VM, in quale folder registrarla, quale port group di rete assegnarle e quale storage policy applicare. Le mapping sono opzionali ma fortemente consigliate: se una VM usa risorse non incluse nei mapping di default, bisogna configurarle manualmente per ogni VM. Gli oggetti che si possono mappare includono risorse di calcolo (cluster, resource pool, host standalone o vApp), cartelle virtuali (folders), port group di rete dedicati alle VM e storage policy.
Per esempio, un mapping tipico potrebbe associare:


Questo significa che tutte le VM nel cluster ProdCluster e nella cartella Prod_VMs saranno collocate nel cluster DR_Cluster e nella cartella DR_VMs_Folder dopo il failover, con la rete mappata da VM_Net_Prod a VM_Net_DR e la storage policy da GoldPolicy a BronzePolicy.
Compute e Folder Mapping
Il resource mapping definisce quale risorsa di calcolo (cluster, pool o host) usare sul sito di DR per le VM protette. Similmente, il folder mapping associa le cartelle di vCenter: se le VM protette si trovano in una certa cartella nel sito primario, il mapping indica in quale folder collocare le VM su DR. Senza folder mapping, SRM crea la VM di recovery nell’inventario di vCenter radice. È buona norma creare mapping espliciti di cartelle e cluster per riflettere l’organizzazione del sito di produzione nel sito di recovery.
Network Mapping e Subnet Mapping
Gli network mapping associano i port group delle VM tra siti. SRM supporta solo la mapping di VM port group (non dei VMkernel port group). In pratica si sceglie per ogni port group di produzione il corrispondente port group di DR. SRM offre mapping automatico per reti e cartelle con nomi identici, oppure si può configurare manualmente. Inoltre è possibile definire mapping di subnet completo: SRM può mappare un’intera subnet del sito primario su un’altra subnet di DR. Questo mantiene lo stesso host address della VM, cambiando solo la parte di network address. Ad esempio, se un VM ha IP 192.168.10.5/24 nel sito primario e la subnet 192.168.10.0/24 è mappata su 10.0.10.0/24, allora la VM avrà IP 10.0.10.5/24 dopo il recovery, eliminando la necessità di personalizzare manualmente gli indirizzi IP.
Storage Policy Mapping
Se le VM protette utilizzano storage policy (ad es. tag VVol o policy di tiering), SRM può proteggere queste VM includendole in protection group basati sulle policy di array-based replication. In fase di failover la VM riceverà l’equivalente storage policy configurato nel sito di DR. Anche se meno comune, configurare correttamente questi mapping evita disallineamenti negli storage policy dopo il failover.
Reverse Mapping e Limitazioni
SRM supporta la creazione di reverse mappings, ossia mapping inversi dal sito di recovery a quello di produzione. Questo è fondamentale per scenari di protezione bidirezionale (failover/reprotect). Attenzione però che non tutti i mapping sono invertibili automaticamente: SRM permette mapping “molti-a-uno” (più oggetti protetti che puntano a uno solo di DR) ma non mapping “uno-a-molti”. In configurazioni molti-a-uno il sito di DR ha meno voci (cartelle, reti) rispetto al primario, e SRM non può generare la mappatura inversa automaticamente per questi casi. In sintesi, i mapping di SRM devono essere coerenti (idealmente uno-a-uno o molti-a-uno) per abilitare correttamente operazioni di re-protect e failback.
Sintesi e Rischi
In mancanza di mapping validi, SRM non sa dove collocare le risorse di rete, calcolo e storage durante il failover. Ciò può provocare errori nel piano di recovery o richiedere interventi manuali in emergenza, aumentando drasticamente il RTO. Per questo una progettazione accurata degli Inventory Mappings – con nomi e strutture coerenti tra siti – è essenziale.
Placeholder VM e Placeholder Datastore
SRM usa le placeholder VM per riservare spazio nell’inventario di vCenter del sito di DR per ogni VM protetta. Al momento della protezione, SRM crea sul sito di recovery una VM “segnaposto” che rappresenta la VM protetta, ma senza dischi virtuali allegati. Queste placeholder VM hanno un’icona speciale nell’inventario, indicano visivamente che la VM è protetta e mostrano il folder e le risorse di calcolo di destinazione. In fase di failover (o test) SRM sostituisce ogni placeholder VM con la vera VM, collegandogli i dischi dai datastore replicati. Finché non viene eseguito il failover, i placeholder VM occupano pochissime risorse (pochi KB) e non necessitano di IP o CPU.
Le placeholder datastores sono i datastore speciali dove vengono salvati i file delle placeholder VM. Questi datastore hanno requisiti specifici: non devono risiedere su dispositivi di storage già replicati (altrimenti verrebbero cancellati o duplicati nel processo di failover); inoltre vanno montati e condivisi tra tutti gli host del cluster di DR. In genere si configura un unico placeholder datastore per sito (protetto e recovery) per abilitare correttamente le operazioni di reprotect. Se non viene specificato alcun placeholder datastore, SRM ne selezionerà uno automaticamente, ma è buona pratica definirlo esplicitamente.
In fase di test o failover, le placeholder VM svolgono un ruolo chiave: prima del failover, visualizzano l’inventario previsto su DR; dopo il failover, vengono eliminate e sostituite dalle VM reali. Senza placeholder VM/Datastore correttamente configurati, SRM non può completare il processo di recovery in modo automatico, perché non esiste un “segnaposto” dove registrare la nuova VM.
Array-Based Replication in SRM
La replica a livello di storage (array-based replication) è uno dei pilastri di SRM per garantire RPO stringenti e supporto VMs con RDM. Per funzionare, SRM si affida a componenti specifici:
Storage Replication Adapter (SRA): è un modulo fornito dal vendor dello storage che permette a SRM di parlare con l’array. L’SRA traduce le richieste di SRM (in ingresso) in comandi comprensibili dall’array, e viceversa. Ogni soluzione di storage supportata ha il proprio SRA, disponibile come file .tar containerizzato da installare nell’appliance di SRM. Dopo l’installazione, è necessario fare un “rescan” affinché SRM riconosca e carichi il nuovo SRA. Tutti gli SRA comunicano tramite XML con SRM e registrano le attività nei log di SRM.
Array Pairs: per abilitare la replica, bisogna configurare SRM su ciascun sito affinché si connetta all’array di storage locale su quel sito. Se esiste una replica array tra due controller (ad esempio array A e array B), in SRM si crea un array pair che associa le credenziali di gestione dei due array. In pratica, si seleziona l’SRA appropriato, si immettono le credenziali per entrambi gli array e si abilita la coppia di array rilevata. Una volta attivato l’array pair, SRM interroga l’SRA per ottenere la lista di tutti i dispositivi replicati tra i due array. SRM quindi lega queste LUN “replicate” alle VM e ai datastore presenti in vCenter (inclusi RDM).
Datastore Groups: SRM utilizza il concetto di datastore group per assicurarsi che tutti i file di una VM siano failover insieme. Un datastore group è il più piccolo insieme di datastore replicati che può essere isolato dagli altri e spostato autonomamente senza perdere coerenza delle VM. SRM calcola automaticamente i datastore group in base a come le VM usano i datastore sul sito protetto. Non è un’impostazione manuale: ad esempio, se la VM1 ha dischi su LUN1 e LUN2, e la VM2 ha dischi su LUN2 e LUN3, SRM potrebbe calcolare due gruppi di datastore (vedi figura seguente). Questo garantisce che LUNs interdipendenti siano sempre failover insieme.
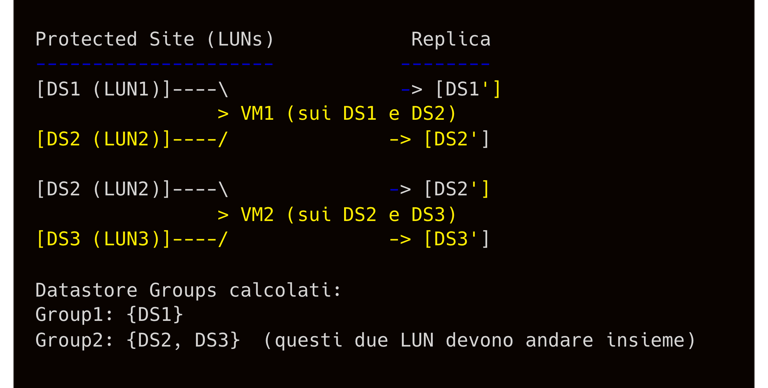
In questo esempio VM1 usa i datastore DS1 e DS2 mentre VM2 usa DS2 e DS3. SRM rileva che DS2 e DS3 sono collegati dalle VM, quindi li raggruppa in un unico Datastore Group. Il risultato è che Group1 contiene solo DS1, e Group2 contiene {DS2, DS3}. Tutti i dispositivi di uno stesso datastore group vengono failover come unità; ciò evita che una VM perda alcuni dischi in caso di failover.
Consistency Group (gruppo di consistenza): a livello di array, i vendor possono definire gruppi di consistenza per unire LUN che vengono replicati con la stessa Policy (ad es. periodicità e atomicità di snapshot/replica). Per un funzionamento ottimale di SRM è importante che la configurazione dei consistency group dell’array rifletta quella dei datastore group calcolati da SRM. In altre parole, idealmente tutte le LUN di un datastore group appartengono allo stesso consistency group sull’array. Questo garantisce che le snapshot e le repliche avvengano sincronamente e che le VM su più LUN rimangano consistenti al momento del failover. Si raccomanda quindi di mantenere i gruppi di consistenza il più semplici possibile, evitando configurazioni che non corrispondono ai datastore group di SRM.
In sintesi, l’Array-Based Replication con SRM richiede un’architettura ben disegnata: occorre installare l’SRA corretto, configurare l’array pair tra i siti, verificare le repliche e lasciare che SRM calcoli i datastore group automaticamente. Un vantaggio chiave di questa soluzione è che può fornire RPO molto bassi (ad esempio sotto i 5 minuti) grazie a replica sincrona o asincrona ad alte prestazioni. Tuttavia bisogna tenere presente che di solito richiede storage hardware dello stesso vendor in entrambi i siti e licenze di replica aggiuntive.
Conclusione
Una corretta implementazione di SRM è un compito complesso ma cruciale. I rischi principali derivano da mappature incomplete o errate: senza inventory mappings appropriati SRM non sa dove allocare le VM in failover, provocando errori o interventi manuali. Analogamente, se i placeholder VM/datastore non sono configurati correttamente, SRM non può gestire automaticamente il recovery dell’inventario. Infine, il design dello storage deve essere allineato con la logica di SRM: ad esempio gruppi di consistenza a livello di array e layout dei LUN devono facilitare (non complicare) il calcolo dei Datastore Group. Pianificare in anticipo queste configurazioni – decidendo in modo coerente i nomi e le strutture delle risorse tra siti, predisponendo placeholder e definendo gruppi di replicazione chiari – è la chiave per un disaster recovery affidabile e ripetibile con VMware SRM.