
NSX Logical Routing Architecture — Parte 3
Routing end-to-end e resilienza: BGP/OSPF, ECMP/HA
Pascal Carone
11/12/202521 min read
Indice
Introduzione
Configurazione end-to-end dei router logici Tier-0 e Tier-1
Creazione di Tier-1 Gateway e segmenti
Creazione di Tier-0 Gateway e uplink segment
Interconnessione Tier-1 ↔ Tier-0 (Router Link)
Route advertisement dal Tier-1 al Tier-0
Route redistribution dal Tier-0 verso gli upstream router
Routing statico: concetti, pro e contro, quando usarlo
Routing dinamico: BGP e OSPF
Border Gateway Protocol (BGP)
Open Shortest Path First (OSPF)
ECMP e High Availability
Equal-Cost Multi-Path (ECMP)
Modalità di High Availability: Active-Active vs Active-Standby
Rilevamento dei guasti con BFD e failover routing
Failover preemptive vs non-preemptive
Conclusione
Introduzione
Nelle prime parti di questa serie abbiamo introdotto l’architettura del routing logico NSX e i suoi componenti fondamentali (Tier-0, Tier-1, Distributed Router, Service Router, ecc). In questa Parte 3 affrontiamo in modo tecnico-operativo la configurazione end-to-end del routing logico a due livelli di NSX, approfondendo sia il routing statico sia il routing dinamico (protocols come BGP e OSPF), e le funzionalità avanzate di equal-cost multipath (ECMP) e alta disponibilità (HA) dei router logici. Al termine, avremo una visione completa su come i Tier-1 Gateway (usati per il traffico East-West) si collegano ai Tier-0 Gateway (usati per il traffico North-South) e su come instradare efficacemente il traffico dalla rete virtuale verso la rete fisica e viceversa.
Configurazione end-to-end dei router logici Tier-0 e Tier-1
Una topologia a due livelli in NSX prevede che i segmenti logici (le reti virtuali connesse alle VM) attacchino un Tier-1 Gateway, il quale a sua volta si collega ad un Tier-0 Gateway per l’uscita verso l’esterno. La configurazione end-to-end di un ambiente di routing logico NSX comprende diversi passi sequenziali, dalla creazione dei gateway fino alla propagazione delle rotte. Di seguito elenchiamo le fasi principali:
Creazione di un Tier-1 Gateway – Tramite l’NSX Manager UI, navighiamo in Networking > Connectivity > Tier-1 Gateways e creiamo un nuovo router logico Tier-1. Questo rappresenta il router distribuito “tenant” che gestirà il traffico East-West (intra-tenant).
Creazione e collegamento dei segmenti al Tier-1 – Creiamo i Segmenti logici (reti L2 virtuali) per le subnet dei workload e li connettiamo al Tier-1 appena creato (Networking > Connectivity > Segments). Ad esempio, segmenti per reti 10.0.1.0/24, 10.0.2.0/24, ecc., verranno associati alle interfacce downlink del Tier-1 Gateway. Ciò permette la connettività East-West: VM su subnet diverse ma collegate allo stesso Tier-1 possono comunicare attraverso il Distributed Router (DR) del Tier-1, senza dover uscire dall’host.
Creazione degli uplink segment per Tier-0 – Prepariamo i segmenti logici di uplink, ovvero reti di transito che connetteranno il Tier-0 ai router fisici upstream. Ad esempio, un segmento di transito 192.168.255.0/30 per collegare Tier-0 ad un router fisico. Questi segmenti si creano in Networking > Connectivity > Segments, tipicamente come segmenti Overlay o VLAN a seconda che il collegamento con l’esterno avvenga via overlay o VLAN su il Transport Node Edge.
Creazione del Tier-0 Gateway – Sempre da NSX Manager (Networking > Connectivity > Tier-0 Gateways), creiamo un router logico Tier-0, che opererà a livello North-South. Durante la creazione, assegniamo al Tier-0 un NSX Edge Cluster su cui gireranno le istanze di Service Router (SR) necessarie per le funzioni centralizzate (come collegamento a uplink fisici, NAT, ecc).
Configurazione degli uplink Tier-0 – Una volta creato il Tier-0, configuriamo le sue interfacce uplink associandole ai segmenti di uplink definiti al passo 3. Ad esempio, assegniamo un’interfaccia Tier-0 su Edge Node con IP 192.168.255.1/30 sul segmento di transito verso l’upstream router (che avrà IP 192.168.255.2/30). Questa operazione avviene modificando il Tier-0 Gateway e aggiungendo External Interfaces collegate agli uplink segment. In questa fase, decidiamo anche la modalità HA (di default Tier-0 è Active-Active) e abilitiamo ECMP se prevediamo di utilizzare più link in parallelo.
Configurazione del routing North-South sul Tier-0 – Impostiamo come il Tier-0 imparerà e pubblicherà le rotte verso la rete fisica. Possiamo configurare routing statico (inserendo manualmente rotte statiche e default route) oppure abilitare un protocollo di routing dinamico (BGP o OSPF) per instaurare adiacenze con i router fisici. Questo aspetto sarà approfondito nelle sezioni successive, ma va pianificato in fase di setup del Tier-0.
Interconnessione del Tier-1 con il Tier-0 – Ora colleghiamo il router Tier-1 al Tier-0 upstream. Modificando il Tier-1 Gateway, lo configuriamo affinché utilizzi come Tier-0 uplink il Tier-0 creato al passo 4 (Tier-1 > Configuration > Linked Tier-0). NSX automaticamente creerà una porta RouterLink tra il Tier-1 (sul suo SR, se esiste) e il Tier-0 (sul DR) e assegnerà un indirizzo IP di transito (di default su subnet 100.64.0.0/16) per la comunicazione interna Tier-1 ↔ Tier-0. Dopo questo collegamento, il Tier-1 diventa figlio del Tier-0, e il Tier-0 conoscerà il next-hop per le reti del Tier-1 tramite la subnet di transit (ad esempio 100.64.x.y).
Abilitazione del Route Advertisement sul Tier-1 – Sul Tier-1 Gateway, abilitiamo la pubblicazione delle rotte locali (collegate al Tier-1) verso il Tier-0. Nella sezione Route Advertisement del Tier-1, selezioniamo le rotte da annunciare (es. rotte delle interfacce collegate, rotte statiche, default route). Questo consente al Tier-0 di apprendere tutte le subnet dei segmenti connessi al Tier-1. Senza questa impostazione, il Tier-0 non avrebbe visibilità delle reti tenant e non potrebbe instradare il traffico verso di esse.
Abilitazione del Route Redistribution sul Tier-0 – Infine, sul Tier-0 configuriamo la redistribuzione delle rotte verso l’esterno. In Tier-0 > Routing > Route Redistribution creiamo regole per ridistribuire determinate rotte (ad esempio, le rotte apprese dal Tier-1, le rotte statiche configurate, le rotte connesse) nei protocolli di routing dinamici (BGP/OSPF) o verso le tabelle di routing del Tier-0 stesso. Questo passaggio è fondamentale se il Tier-0 utilizza BGP o OSPF: ad esempio, per fare in modo che un router fisico upstream impari attraverso BGP le reti dei tenant presenti dietro il Tier-0, bisogna redistribuire nel BGP del Tier-0 le rotte connesse (o di Tier-1). Nel caso di routing statico puro con default route, il route redistribution serve soprattutto per ridistribuire rotte di Tier-1 nella tabella Tier-0 (già coperto dal punto 8) oppure non è necessario se si usano solo rotte statiche manuali lato fisico.
A questo punto abbiamo un routing logico end-to-end: le VM nei segmenti logici connesse al Tier-1 possono comunicare Nord-Sud con l’esterno tramite il Tier-0. Possiamo verificare la connettività East-West (tra VM su segmenti differenti ma stesso Tier-1) e la connettività North-South (tra una VM interna e un IP esterno) usando strumenti di test (ping, tracert) e la vista Network Topology in NSX Manager. Quest’ultima fornisce un diagramma in tempo reale mostrando i segmenti attaccati al Tier-1, il Tier-1 collegato al Tier-0 e gli uplink del Tier-0 verso l’esterno, utile per validare la correttezza delle configurazioni.
Ecco un semplice schema ASCII della topologia a due tier appena descritta:


Nell’ASCII sopra, più segmenti logici (A, B, C) sono connessi al Tier-1 Gateway. Il Tier-1 è collegato tramite una porta di transit (RouterLink) al Tier-0 Gateway, che infine si collega con uplink fisici al router upstream.
Route advertisement dal Tier-1 al Tier-0
Per permettere al Tier-0 di conoscere le reti dei tenant configurate sui Tier-1 (cioè le subnet dei segmenti logici), NSX utilizza il meccanismo di Route Advertisement. In pratica, il Tier-1 annuncia al Tier-0 le proprie rotte interne. Sul Tier-1 Gateway troviamo impostazioni granulari di route advertisement: possiamo scegliere di pubblicare le rotte direttamente connesse (segmenti), le rotte statiche eventualmente configurate sul Tier-1, le rotte apprese via BGP locale (poco comune su Tier-1) e l’eventuale default route presente sul Tier-1. Abilitando queste opzioni, tutte le reti del Tier-1 diventano note al Tier-0, che le installerà nella propria routing table come rotte verso il Tier-1 via RouterLink.
È importante notare che di default un Tier-1 non pubblica alcuna rotta al Tier-0 finché non abilitiamo esplicitamente il route advertisement. Questa scelta progettuale garantisce isolamento multi-tenant: un amministratore cloud può decidere quali subnet tenant esporre al Tier-0 (ad esempio solo alcune subnet e non altre, se si vuole filtrare). In un contesto single-tenant invece normalmente si annunciano tutte le rotte connesse.
Dal punto di vista pratico, dopo aver collegato Tier-1 e Tier-0, navighiamo nella configurazione del Tier-1 e abilitiamo le categorie di rotte da propagare. Ad esempio, spuntiamo Connected Segments and Service Ports (rotte direttamente connesse) e Static Routes se il Tier-1 ha rotte statiche configurate. Una volta fatto, sul Tier-0 (nella sezione Routing) dovremmo vedere le rotte del tenant comparire, con next-hop sull’interfaccia di transit (RouterLink) che punta al Tier-1.
Route redistribution dal Tier-0 verso gli upstream router
Mentre il route advertisement riguarda la direzione Tier-1 verso Tier-0, il concetto di Route Redistribution in NSX si applica soprattutto dal Tier-0 verso l’esterno. Il Tier-0 infatti è il punto di confine tra il dominio virtuale NSX e la rete fisica: deve quindi comunicare ai router fisici quali reti sono raggiungibili “dietro” di lui (cioè nei Tier-1). Se sul Tier-0 utilizziamo protocolli dinamici (BGP/OSPF), sarà necessario configurare la redistribuzione delle rotte interne di NSX nei protocolli.
In NSX, la Route Redistribution sul Tier-0 si configura definendo regole che specificano quali rotte includere. Possiamo scegliere di redistribuire: le rotte connected (le subnet collegate alle interfacce del Tier-0, inclusa la transit verso Tier-1), le rotte static presenti sul Tier-0, le rotte apprese dai Tier-1 collegati, le rotte di service (NAT, LB VIP) e così via. Ad esempio, per propagare verso i router fisici le reti dei tenant, selezioneremo la redistribuzione delle Connected (che include le rotte di transit per Tier-1) e delle Tier-1 static/routes (che includono le rotte pubblicizzate dal Tier-1) nel protocollo BGP/OSPF abilitato sul Tier-0. In questo modo, il Tier-0 inserirà nel processo di routing dinamico tutte le rotte interne, e i vicini upstream le apprenderanno come rotte raggiungibili tramite il Tier-0.
Se il Tier-0 invece fa uso di routing statico (nessun protocollo dinamico), il route redistribution verso l’esterno non è applicabile in senso stretto, poiché i router fisici non apprendono dinamicamente nulla: in tal caso le rotte verso i tenant devono essere configurate manualmente anche sugli upstream router, oppure più comunemente si configura una default route dal router fisico verso il Tier-0 (instradando tutto il traffico destinato ai tenant verso NSX) e viceversa dal Tier-0 verso il fisico. Un esempio tipico: il Tier-0 ha una default route statica verso l’upstream, e l’upstream router ha una route statica aggregata (es. 10.0.0.0/16) che inoltra tutto il traffico destinato ai tenant verso l’indirizzo IP dell’uplink Tier-0. In contesti più complessi però, i protocolli dinamici e la redistribuzione sono preferibili per ridurre la configurazione manuale e gli errori.
Routing statico: concetti, pro e contro, quando usarlo
Il routing statico è la forma più basilare di instradamento: consiste nel configurare manualmente rotte fisse nelle tabelle di routing dei router, in modo che puntino a un next-hop prestabilito. In NSX, sia i Tier-0 che i Tier-1 supportano la configurazione di rotte statiche. Ad esempio, sul Tier-0 potremmo configurare una default route che instrada tutto il traffico sconosciuto verso l’IP del router fisico upstream. Sul Tier-1, potremmo configurare una statica per instradare una specifica subnet verso un servizio in uscita (anche se questo è meno comune).
Pro e contro: La natura statica di queste rotte ha vantaggi e svantaggi. Da un lato, le rotte statiche sono semplici da configurare e offrono controllo totale all’amministratore su come il traffico viene instradato. Possono essere ottimizzate per scegliere percorsi specifici (fine-tuning) e non introducono la complessità dei protocolli di routing. Inoltre, non annunciano informazioni di rete sulla rete (migliorando la sicurezza, non essendoci scambio di rotte con terzi). D’altro canto, non si adattano automaticamente ai cambiamenti topologici: se un percorso diventa irraggiungibile, il router statico non lo rimuove dalla tabella a meno che un amministratore intervenga. Ciò comporta limitata scalabilità, poiché gestire manualmente molte rotte diventa oneroso e soggetto a errori. Anche la ridondanza e failover richiedono interventi manuali: l’amministratore deve prevedere tutti i possibili guasti e configurare rotte di backup (ad esempio attraverso metriche/AD più alte) per ciascun scenario. In sintesi, il routing statico funziona bene in reti semplici o molto controllate, ma non è adatto a infrastrutture in rapida evoluzione.
Quando usarlo: In contesti reali, le rotte statiche si utilizzano tipicamente per:
Reti di piccole dimensioni o molto stabili, dove i percorsi non cambiano praticamente mai.
Link di tipo stub o point-to-point, dove un router ha una sola via d’uscita (es. un Tier-0 connesso a un unico router upstream può usare una default route statica verso quest’ultimo).
Default route verso ISP o DMZ: è comune configurare manualmente una default route dal Tier-0 all’ISP, e viceversa una static route sull’ISP verso il Tier-0 per i prefissi del data center.
Backup di emergenza: rotte statiche con Administrative Distance più alta possono fare da percorso di riserva nel caso falliscano i protocolli dinamici. Ad esempio, possiamo impostare una route statica come failover se BGP smette di funzionare.
In conclusione, il routing statico su NSX va bene per deployment semplici o in casi specifici (ad es. collegamento di ambienti di test, DMZ isolate, ecc.), mentre in ambienti enterprise o multi-tenant dove le reti sono numerose e soggette a cambiamenti è preferibile automatizzare l’instradamento con protocolli dinamici.
Routing dinamico: BGP e OSPF
Il routing dinamico permette ai router di scambiarsi automaticamente informazioni sulle rotte, adattandosi ai cambiamenti della rete in tempo reale. NSX-T (NSX Data Center) supporta i protocolli dinamici più comuni a livello di Tier-0: BGP (Border Gateway Protocol) e OSPF (Open Shortest Path First). Questi protocolli vengono eseguiti dai Service Router (SR) del Tier-0 sulle NSX Edge Nodes, poiché sono processi di controllo centralizzati (il Distributed Router (DR), invece, non partecipa direttamente ai peerings). Vediamo come funzionano e come si configurano in NSX.
Dal punto di vista del Tier-0:
BGP può essere usato sia in modalità eBGP (peer con AS differenti, tipicamente per collegarsi ai router fisici dell’azienda o ISP) sia in iBGP (peer nello stesso AS, ad esempio tra più istanze SR del Tier-0 o con altri router interni). In genere il Tier-0 avrà un proprio Autonomous System Number (ASN) configurato, differente da quello della rete fisica, quindi la peering con i router upstream sarà eBGP. Tuttavia NSX consente anche la configurazione iBGP, utile se per esempio il Tier-0 deve partecipare a un AS interno all’azienda o se vogliamo fare peering tra due Tier-0 logicamente separati ma nella stessa AS.
OSPF può operare su network type Point-to-Point oppure Broadcast. Questo significa che gli uplink del Tier-0 possono instaurare adiacenze OSPF su reti di transito dedicate (p2p, ad es. /30) o su segmenti condivisi con più router (broadcast, dove avviene elezione di un Designated Router). La scelta dipende dalla topologia fisica: se ogni Edge Node Tier-0 parla con un singolo upstream router su un link dedicato, p2p è più efficiente; se invece il Tier-0 è collegato a una VLAN con più router (ad es. HSRP/VRRP cluster), si userà broadcast.
Border Gateway Protocol (BGP)
Panoramica: BGP è un protocollo di routing esterno (EGP) utilizzato per connettere domini autonomi distinti. Nel contesto NSX, BGP viene usato sul Tier-0 per scambiare rotte con i router fisici upstream (tipicamente i core router del data center o dell’ISP). Il Tier-0 agisce come router BGP e annuncia le reti virtuali (dei Tier-1) all’esterno, imparando al contempo eventuali rotte esterne da inoltrare alle VM interne (ad es. subnet di altri siti, rotte Internet, ecc). BGP in NSX supporta sia eBGP che iBGP, anche se lo scenario più comune è eBGP con ciascun vicino fisico. Inoltre, NSX supporta fino a 8 percorsi in ECMP via BGP.
Configurazione di BGP su Tier-0: La configurazione avviene tipicamente via interfaccia grafica NSX Manager:
Si accede alla sezione Tier-0 > Routing > BGP. Per prima cosa si abilita BGP sul Tier-0 (di default è disabilitato) e si configura l’AS number locale per il Tier-0 (ad es. ASN 65001) e l’EBGP Multihop se necessario (non comune per uplink diretti).
Si aggiungono quindi i Neighbor BGP, specificando l’indirizzo IP del router fisico peer, il suo ASN (es. 65000), e l’interfaccia source/local IP del Tier-0 da cui partirà la sessione (cioè l’IP dell’uplink Tier-0). Si può anche regolare altri parametri come i timer (hold time, keepalive) o attivare l’autenticazione MD5 per sicurezza, se supportata dall’altro lato.
Un semplice scenario con due peer eBGP potrebbe essere: il Tier-0 (AS 65001) effettua peering con due router fisici dell’underlay (entrambi AS 65000) su due uplink distinti. In ASCII:


Schema: Il Tier-0 ha due sessioni eBGP attive, una con Router 1 e l’altra con Router 2, appartenenti all’AS esterno 65000. Entrambi i peer ricevono dal Tier-0 le rotte dei tenant e forniscono al Tier-0 le rotte esterne. Configurando ECMP, il traffico North-South può bilanciarsi su entrambi i link.
Dopo aver configurato i peer, si procede a impostare quali rotte il Tier-0 annuncerà via BGP. Questo è collegato alle Route Redistribution discusse prima: nel tab Route Redistribution creiamo o verifichiamo esista una regola che redistribuisca in BGP le rotte di Tier-1/connected/static desiderate. In alternativa, in ambiente semplice potremmo anche inserire manualmente delle Network in BGP (funzionalità che inserisce in BGP delle rotte presenti nella routing table del Tier-0, simile al comando network di BGP tradizionale).
Infine, verifichiamo lo stato delle sessioni BGP e delle rotte. Dal NSX Manager UI (o via API/CLI) controlliamo che i BGP Neighbors risultino Established e scambino le route previste. In UI si trova una lista dei neighbor con relativo stato (Up/Down) e informazioni di scambio prefissi. Possiamo anche usare il CLI sul Edge Node: ad esempio il comando get bgp neighbor o get bgp route nell’Edge Node (all’interno del VRF del Tier-0) per vedere i dettagli come si farebbe in un router tradizionale.
BGP Route Aggregation (Summarization): Un aspetto avanzato di BGP è la possibilità di aggregare (sommarizzare) le rotte. NSX Tier-0 supporta la Route Aggregation configurabile nella sezione BGP: questa funzione consente di annunciare intenzionalmente un prefisso più sintetico al posto di molte rotte specifiche. Ad esempio, se i tenant hanno reti 10.10.1.0/24, 10.10.2.0/24, 10.10.3.0/24, si può configurare un’aggregazione in BGP per pubblicare solo 10.10.0.0/16 verso l’esterno. Ciò riduce la dimensione delle tabelle di routing dei router fisici, diminuisce il numero di rotte annunciate e velocizza i calcoli di best path BGP. L’aggregazione va usata con criterio, assicurandosi che le reti aggregate siano contigue e che non si rischi di nascondere dettagli di routing necessari. Nel nostro esempio, un’unica rotta /16 potrebbe essere accettabile se tutte le subnet /24 sono dietro NSX; ma se solo metà di quelle reti esistessero, un’aggregazione troppo ampia potrebbe far dirigere traffico verso il Tier-0 per destinazioni inesistenti. In NSX l’aggregazione BGP si configura indicando il prefix aggregato e lasciando che il Tier-0 annunci solo quello (a patto che esista almeno una route more specific corrispondente nella sua tabella).
Open Shortest Path First (OSPF)
Panoramica: OSPF è un protocollo di routing dinamico di tipo link-state, ampiamente usato nelle reti enterprise. Su NSX Tier-0, OSPF può essere usato al posto di BGP per scambiare rotte con l’esterno, tipicamente quando l’azienda usa OSPF nell’infrastruttura fisica. A differenza di BGP, OSPF non usa concetto di AS ma di Area. Il Tier-0 potrebbe diventare, ad esempio, un router ABR se connesso ad Area 0 lato fisico e a un’altra area lato NSX (anche se spesso NSX Tier-0 viene messo in Area 0 direttamente).
Configurazione di OSPF su Tier-0: Nel NSX Manager UI, sotto Tier-0 > Routing > OSPF, si abilita OSPF (di default è off):
Bisogna prima assegnare il Router ID (un identificatore in forma di IP, es. 10.255.255.1) e creare almeno un’Area OSPF. Ad esempio, configuriamo Area 0.0.0.0 (Area 0).
Per ogni interfaccia uplink del Tier-0 che parteciperà a OSPF, si abilita OSPF specificando l’area a cui appartiene. Se l’uplink è una connessione punto-punto a un router, si può impostare Network Type: P2P, evitando l’elezione di DR/BDR e rendendo più rapida la convergenza. Se invece l’uplink è una VLAN condivisa con più router, si lascia Broadcast (predefinito) così che possano gestire l’elezione di un DR. Ad esempio, abilitiamo OSPF su uplink Tier-0 verso RouterA in Area 0, network type P2P se è un link dedicato /30.
Una volta attivato, il Tier-0 inizierà a inviare Hello Packets OSPF e a formare adiacenze con i router vicini sulla stessa area. Possiamo quindi controllare lo stato dei neighbor dal UI (lista di neighbor OSPF con stato Full) o via CLI (get ospf neighbor).
Similmente a BGP, anche per OSPF occorre configurare quali rotte annunciare. Nel tab Route Redistribution del Tier-0 definiremo quali rotte interne NSX redistribuire in OSPF (tipicamente Connected + Tier-1 routes come discusso). Il Tier-0 le pubblicherà tramite LSA di tipo 5 (rotte esterne) nell’area OSPF. Inoltre, è prassi configurare sul Tier-0 se deve propagare o meno una Default Route in OSPF: NSX consente di segnare “Default Originate” per far sì che il Tier-0 annunci 0.0.0.0/0 nell’area (utile se NSX è via d’uscita verso internet).
Verifica e route summarization in OSPF: Si dovrebbe verificare che le rotte dei tenant compaiano nella LSDB/ROUTE dei router fisici come External LSAs (Type 5) originate dal Tier-0. Dalla UI NSX possiamo vedere lo stato OSPF (neighbor up, LSAs count), oppure via CLI con get ospf route per vedere le rotte apprese/inviate.
Per quanto riguarda la summarization, anche OSPF supporta l’aggregazione di rotte, ma con meccanismi diversi da BGP. In NSX, è possibile configurare una Route Summarization al confine di un’Area (ad esempio se Tier-0 è ABR tra Area 0 e Area 1), oppure più tipicamente riassumere le rotte esterne annunciate. Dal UI di Tier-0 > OSPF, c’è la sezione Route Summarization dove definire eventuali network summary da applicare. Summarizzare rotte in OSPF aiuta a ridurre il flooding di LSAs, a risparmiare CPU e memoria su router (meno rotte distinte da calcolare) e a semplificare il troubleshooting perché le tabelle sono più leggere. Ad esempio, se Tier-0 deve annunciare in Area 0 le reti 172.16.10.0/24, 172.16.11.0/24 e 172.16.12.0/24 appartenenti ai tenant, potremmo fare una summarization in 172.16.8.0/21 così che un solo LSA rappresenti tutte e tre le reti. Naturalmente, bisogna assicurarsi che nessuna rete estranea rientri in quell’intervallo per non perdere specificità. In generale, la summarization OSPF va usata soprattutto in large-scale environments con tante rotte, per mantenere OSPF efficiente.
ECMP e High Availability
L’Equal-Cost Multi-Path (ECMP) e l’High Availability (HA) dei Tier-0 Gateway sono due caratteristiche chiave che permettono a NSX di ottenere sia prestazioni maggiori che resilienza ai guasti. ECMP consente di usare più link in parallelo per il traffico, mentre le modalità HA definiscono come i router logici Tier-0 si comportano in cluster di Edge Node (attivo-attivo o attivo-standby). Esaminiamo prima ECMP e poi le modalità HA con i relativi meccanismi di failover.
Equal-Cost Multi-Path (ECMP)
L’ECMP è una tecnica che permette di avere più percorsi di costo identico verso la stessa destinazione e di usarli contemporaneamente per bilanciare il traffico. Nel contesto di NSX Tier-0, ECMP si traduce nella possibilità di configurare molteplici uplink attivi sul Tier-0 verso router fisici upstream, sfruttando più Edge Node in parallelo. NSX Tier-0 supporta fino a 8 percorsi ECMP paralleli. Questo significa che possiamo avere, ad esempio, 2 Edge Node ciascuno con un uplink verso un router fisico primario e secondario, ottenendo 4 vie attive (2 per Edge) se tutte hanno lo stesso costo e priorità.
Caratteristiche di ECMP in NSX:
Aumento di banda: con N link attivi si moltiplica la capacità di traffico North-South gestibile, combinando la throughput di ciascun uplink.
Bilanciamento del carico: il traffico viene hashato (in base a 5-tuple: sorgente, destinazione IP, porta sorgente, porta destinazione, protocollo) per distribuirsi sui diversi path in maniera (pseudo)equilibrata. Questo evita congestione su un singolo link quando altri sono liberi.
Fault Tolerance: se uno dei percorsi ECMP fallisce, il traffico viene automaticamente indirizzato sugli altri rimasti, garantendo resilienza senza tempi di failover percepibili (dal momento che le rotte alternative erano già attive in tabella).
In NSX, l’ECMP si attiva automaticamente nel momento in cui abilitiamo un protocollo di routing dinamico sul Tier-0 (BGP o OSPF). Infatti, ECMP è attivo di default con BGP e OSPF, supponendo che esistano percorsi multipli di pari costo. È comunque possibile disabilitarlo (ad esempio per BGP c’è un flag “Enable ECMP” nella config). Nel caso di routing statico, ECMP può essere realizzato configurando più rotte statiche con la stessa metrica verso next-hop differenti.
Ecco un esempio semplificato di Tier-0 con due uplink in ECMP verso due router fisici:
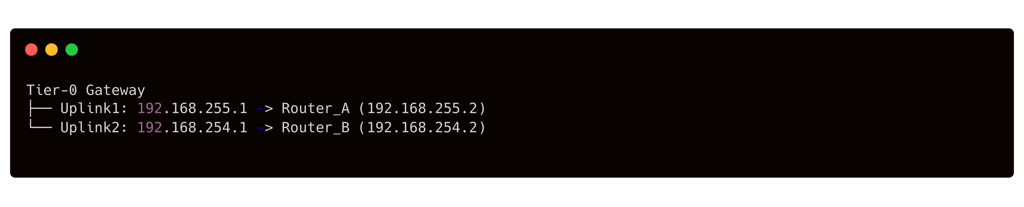

In questo esempio, il Tier-0 ha due uplink (su subnet diverse) connessi a Router A e Router B. Se entrambe le vie forniscono accesso alle stesse reti esterne, il Tier-0 installerà due rotte di costo uguale. Il traffico verso l’esterno verrà suddiviso su Uplink1 e Uplink2 (per esempio, usando un hash su IP/porta) e in caso di caduta di uno dei due router o link, tutto il traffico verrà instradato sull’altro percorso.
Dal punto di vista operativo, una volta configurato BGP/OSPF con due peer (come nell’esempio del paragrafo BGP), l’ECMP è già in funzione se le rotte apprese da entrambi i peer hanno lo stesso valore di costo/metric (in OSPF) o local preference/AS-PATH equivalent (in BGP). Conviene verificare che effettivamente il Tier-0 veda entrambe le rotte. Ad esempio, con CLI get route sul Tier-0 si dovrebbero vedere due next-hop per la stessa destinazione.
Modalità di High Availability: Active-Active vs Active-Standby
I Tier-0 Gateway sono distribuiti su Edge Node per fornire servizi centralizzati e connettività North-South. Per garantire ridondanza, un Tier-0 può operare in due modalità di alta affidabilità:
Active-Active HA – Tutti gli Edge Node che ospitano il Tier-0 sono attivi simultaneamente e instradano traffico in parallelo. Questa è la modalità predefinita per i Tier-0. In Active-Active, il carico viene distribuito fra gli Edge (grazie anche a ECMP). Storicamente, in NSX-T pre-4.0, Active-Active supportava solo servizi stateless (routing, NAT stateless) mentre servizi stateful come NAT e Gateway Firewall richiedevano active-standby. Dalla versione NSX 4.0.1 vi è un miglioramento: anche servizi stateful (NAT, etc.) sono supportati in Active-Active, rendendo questa modalità ancora più attraente.
Active-Standby HA – In questa modalità (spesso usata per Tier-1 o Tier-0 che fanno NAT prima di NSX 4.0.1), solo un Edge Node alla volta è attivo per quel router logico, l’altro rimane in standby pronto a subentrare. Il traffico Nord-Sud passa tutto dall’Edge attivo; il secondo Edge subentra solo se il primo fallisce. Active-Standby garantisce semplicità e supporto pieno a servizi stateful (poiché tutto il traffico passa sempre da un unico nodo, mantenendo sessioni, ecc). Ha come svantaggio che la capacità di throughput è limitata a un singolo Edge alla volta (non c’è utilizzo parallelo di risorse).
Vediamo i comportamenti specifici di queste modalità in termini di routing:
In Active-Active, se abbiamo ad esempio due Edge Node, entrambi ospitano un’istanza del Tier-0 SR attiva. Ciascun SR farà peering dinamico con i router fisici. Ad esempio, con BGP attivo-attivo: entrambi gli SR stabiliscono sessioni BGP con il router fisico upstream. Le route apprese dai due Edge vengono poi condivise (NSX Controller o iBGP interno) affinché il DR distribuito possa mandare il traffico su entrambi. Il traffico in ingresso dai router fisici è suddiviso tra i due Edge (grazie a ECMP su due next-hop). Con OSPF in active-active, similmente, entrambi gli SR formano adiacenza OSPF con i router fisici (usando lo stesso cost) e il DR distribuito bilancia traffico su entrambi. Il risultato è che tutti gli Edge attivi partecipano e condividono il carico, aumentando resilienza e banda. Nota: in Active-Active, se sono in gioco servizi stateful come NAT, NSX assegna in modo deterministico ad ogni Edge la gestione di specifici flussi (p.e. in base a IP hash) così che le risposte tornino dallo stesso Edge.
In Active-Standby, solo l’Edge primario (Active) instrada traffico e forma peerings. Ad esempio, con BGP in active-standby: il Tier-0 avrà due SR (uno per Edge) ma solo l’istanza Active realmente inoltra traffico, mentre la Standby mantiene comunque la sessione BGP con i router fisici in established ma manipola gli annunci per non farsi usare. In particolare, il Tier-0 Standby fa AS-path prepend sulle rotte che annuncia, scoraggiando l’upstream dall’instradare traffico verso di lui finché l’Active è vivo. Quindi gli upstream router vedono due peer BGP (due IP di Edge) ma preferiscono il percorso via Active (perché quello via Standby è più lungo come AS-PATH). Inoltre, il Distributed Router (DR) di NSX invia comunque tutto il traffico verso l’SR Active, ignorando lo Standby. Nel caso di OSPF in active-standby, un meccanismo simile è ottenuto settando sul router Standby un costo molto alto sulle rotte, così che gli upstream OSPF preferiscano sempre il peer Active. In sintesi, lo Standby è passivo per il forwarding finché l’Active funziona, ma rimane pronto e relativamente allineato (sessioni BGP up, tabelle pronte) per subentrare in caso di failover.
Rilevamento dei guasti con BFD e failover routing
In un ambiente ridondato (active-standby o active-active), rilevare rapidamente il guasto di un Edge Node o di un percorso è cruciale per effettuare il failover senza interrompere il traffico. NSX utilizza due meccanismi principali per il failover detection:
BFD (Bidirectional Forwarding Detection): è un protocollo leggero di keepalive che rileva velocemente (in millisecondi) la perdita di connettività su un percorso. NSX attiva sessioni BFD sia sulla Management & Tunnel network tra Edge e Manager/Hosts, sia sugli uplink overlay tra Tier-0 e Tier-1. I messaggi BFD sono scambiati a intervalli regolari; se per un breve periodo non si ricevono reply, si considera down. In HA, NSX usa BFD per capire se l’istanza attiva è isolata: se uno Standby smette di ricevere BFD dall’Active (sia a livello management link che overlay link), assumerà che l’Active sia andato giù e innescherà il failover diventando Active. BFD offre un rilevamento molto rapido rispetto ai timer di routing protocol standard, ed è indipendente dal tipo di link (funziona anche su link fisici che non hanno altri segnali di fault).
Protocollo di Routing Dinamico: anche i segnali dai protocolli BGP/OSPF stessi sono usati. Ad esempio, in active-active se un Edge perde tutte le adiacenze BGP/OSPF con i vicini fisici (ad es. perché il collegamento di uplink è caduto), NSX può rilevare che quell’Edge non è più utile per inoltrare traffico esterno. Nel caso di Active-Standby, se l’istanza Active perde i peer dinamici su tutti gli uplink, viene interpretato come un evento di isolamento dall’esterno e si attiva il failover. In pratica, l’Edge Active “cede il passo” e lo Standby diventa Active, ristabilendo le sessioni di routing e riprendendo il traffico.
Questi due meccanismi lavorano congiuntamente per gestire diversi tipi di fault: BFD copre soprattutto il caso di fallimento completo dell’Edge Node (es. crash o perdita di connettività totale), mentre il monitoraggio BGP/OSPF copre il caso di perdita di peering uplink. In entrambi i casi, NSX effettua un failover orchestrato: il Tier-0 Standby prende lo stato di Active.
Failover preemptive vs non-preemptive
Quando un Edge Node guasto torna operativo, si pone la domanda: deve riprendersi il ruolo Active automaticamente oppure no? NSX offre due modalità di failback configurabili per i router in Active-Standby:
Preemptive – L’Edge preferito (quello originariamente Active, o marcato come Preferred) riprende il ruolo di Active automaticamente quando torna disponibile. In altre parole, si “pre-impone”: se era il master designato, dopo un failover temporaneo al secondario, al suo ritorno riprende possesso e l’altro torna Standby. Questa modalità garantisce che, dopo guasti transitori, la topologia ritorni sempre alla configurazione iniziale (potenzialmente desiderata per uniformità, o perché l’Edge primario è più potente, ecc). Tuttavia, può causare un doppio movimento (failover e poi failback) in breve tempo se il nodo primario rientra, introducendo un altro momento di disservizio minimo.
Non-Preemptive – L’Edge che ritorna operativo rimane in standby se il suo peer sta attualmente facendo l’Active. In pratica, si evita di forzare un nuovo failover: il nodo rientrato aspetta e riprende il ruolo Active solo se l’attuale Active dovesse cadere a sua volta. Questa modalità privilegia la stabilità: una volta che c’è stato un failover, non si altera nuovamente lo stato finché non è necessario. È spesso consigliata per evitare oscillazioni in caso di flapping (guasti ripetuti).
La scelta fra preemptive e non dipende dalle esigenze: se si vuole sempre utilizzare un nodo “primario” quando disponibile, si userà preemptive; se si preferisce minimizzare i cambi di stato e lasciare che il backup resti master finché va, si userà non-preemptive. Per configurarla, nell’NSX UI alla voce Ha Mode del Tier-0 in Active-Standby si trova l’opzione di failover mode.
Conclusione
In questa terza parte abbiamo esplorato in dettaglio l’architettura di routing logico NSX dal punto di vista operativo: come creare e collegare i Tier-1 e Tier-0 Gateway con i relativi segmenti e uplink, come abilitare la pubblicazione e redistribuzione delle rotte per ottenere connettività completa, e le differenze tra instradamento statico e dinamico. Abbiamo approfondito la configurazione di BGP e OSPF su NSX, con esempi di come aggiungere peer e verificare lo stato, includendo tecniche di ottimizzazione come la route aggregation/summarization per mantenere le tabelle di routing snelle. Infine, ci siamo concentrati sulle funzionalità di ECMP (che massimizza le prestazioni usando più path paralleli) e di High Availability dei router logici, spiegando le modalità Active-Active e Active-Standby del Tier-0, il ruolo del BFD e dei protocolli nel rilevare i guasti, e le strategie di failover preemptive vs non-preemptive.
Con queste conoscenze, un infrastructure engineer ha gli strumenti per costruire una rete virtuale resiliente e ottimizzata, in cui il traffico dei tenant viene instradato in modo efficiente all’interno dell’SDDC e verso l’esterno. Nel prossimo articolo approfondiremo ulteriori aspetti avanzati (ad esempio integrazioni con contesti multi-Tenant/VRF, se previsti) e casi d’uso pratici del routing logico NSX. Continuiamo dunque ad esplorare le potenzialità di NSX nel trasformare l’architettura di rete dei moderni data center.