
Architettura di VMware NSX
Management Cluster, Control Plane e Data Plane
Pascal Carone
1/9/202518 min read
Indice
Introduzione
Virtual Cloud Network e ruolo di VMware NSX
Architettura di NSX:
3.1 Management Plane e NSX Manager
3.2 Control Plane centralizzato e locale
3.3 Data Plane e nodi di trasporto
3.4 Appliance Proxy Hub e NSX-RPC
NSX Manager Cluster ed Alta Disponibilità
4.1 Cluster a tre nodi e database distribuito
4.2 Modalità Virtual IP vs Load Balancer
Architettura interna di NSX Manager: Policy, Proton, CorfuDB, Reverse Proxy
Esempi di utilizzo pratico di NSX
Microsegmentazione
Automazione della rete
Sicurezza distribuita
Conclusione
Introduzione
La virtualizzazione di rete svolge un ruolo fondamentale nell'offrire agilità, sicurezza e coerenza operativa. VMware ha introdotto il concetto di Virtual Cloud Network (VCN) come un framework software ubiquitario che connette e protegge carichi di lavoro su qualsiasi ambiente. In pratica, la Virtual Cloud Network è uno strato software che fornisce connettività tra data center, cloud e sedi periferiche, garantendo al contempo visibilità sui dati e sicurezza. Al centro di questo paradigma troviamo VMware NSX, la piattaforma di virtualizzazione di rete che funge da tecnologia portante per realizzare la Virtual Cloud Network. NSX permette di ottenere networking e sicurezza in maniera consistente su tutto l'ambiente IT, indipendentemente dall'infrastruttura fisica sottostante o dal cloud utilizzato.
Questo articolo fornisce una panoramica tecnica sull'infrastruttura VMware NSX. Esploreremo l'architettura di NSX con particolare attenzione al componente NSX Manager, approfondendo i suoi Plane (management, control, policy), la struttura a cluster di tre nodi per alta disponibilità, le modalità di fruizione tramite Virtual IP o Load Balancer, e i flussi di lavoro interni che coinvolgono componenti come Proton, CorfuDB e il Reverse Proxy. Verranno inoltre descritti i principali componenti dell'architettura NSX ed il loro funzionamento. In conclusione, discuteremo alcuni casi d'uso pratici di NSX, come la microsegmentazione, l'automazione della rete e la sicurezza distribuita, per contestualizzare come queste funzionalità abilitano il Virtual Cloud Network nel mondo reale.
Virtual Cloud Network e ruolo di VMware NSX
Con Virtual Cloud Network si intende un framework introdotto da VMware per estendere il networking e la sicurezza in maniera uniforme su qualunque cloud, qualunque infrastruttura, qualunque applicazione e dispositivo. In altre parole, è una visione architetturale in cui la rete diventa un tessuto software omnipresente che collega e protegge tutti i carichi di lavoro, ovunque essi risiedano Questo approccio nasce dall'esigenza di superare i confini tradizionali della rete fisica, offrendo connettività agile e sicurezza integrata sia all'interno del data center, sia tra ambienti cloud pubblici/privati e l'edge.
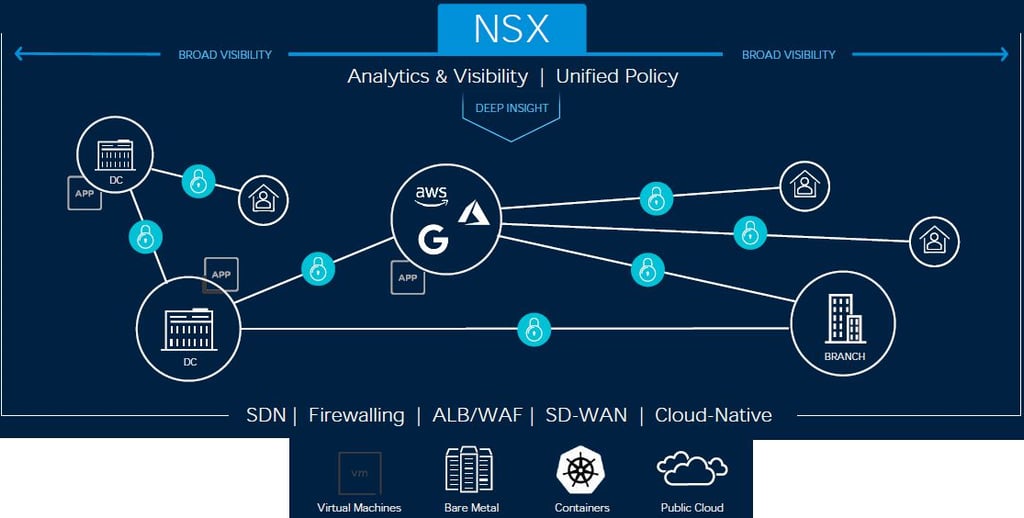
Il portafoglio VMware alla base della Virtual Cloud Network comprende diverse soluzioni, ma NSX ne è il componente cardine. VMware NSX (evoluzione di NSX-T Data Center, ora semplicemente chiamato NSX nella versione 4.x) fornisce una piattaforma unificata di Software-Defined Networking (SDN) che realizza virtualmente tutti i servizi di rete e sicurezza, dal switching e routing logico al firewall distribuito, fino all'integrazione con strumenti di automazione e policy avanzate. Grazie a NSX, le organizzazioni possono implementare reti completamente virtualizzate sopra qualunque infrastruttura sottostante, ottenendo benefici chiave quali: isolamento e segmentazione avanzata del traffico (microsegmentazione), network overlay per collegare ambienti diversi, automazione nella creazione e gestione delle reti, e controllo centralizzato delle policy di sicurezza.
In sintesi, NSX è il motore che concretizza la vision della Virtual Cloud Network, offrendo coerenza operativa e sicurezza end-to-end attraverso ambienti eterogenei. Nel seguito dell'articolo analizzeremo in dettaglio come NSX sia architetturato per raggiungere questi obiettivi, partendo dalla suddivisione in piani logici fino ai meccanismi interni del suo management cluster.
Architettura di NSX: Piani di gestione, controllo e dati
L'architettura di VMware NSX si basa su una suddivisione concettuale in tre Plane principali: Management Plane (piano di gestione), Control Plane (piano di controllo) e Data Plane (piano dei dati). Questa separazione architetturale è fondamentale poiché consente di scalare la piattaforma senza impattare i carichi di lavoro, isolando le funzioni di gestione e controllo dalla movimentazione effettiva dei pacchetti. In un ambiente NSX on-premises, questi piani interagiscono strettamente ma hanno responsabilità distinte, come descritto di seguito.
Management Plane e NSX Manager
Il Management Plane è responsabile dell'interfaccia utente (UI) e programmatica (API REST) attraverso cui gli amministratori configurano il comportamento desiderato della rete virtuale. In NSX, il management plane è incarnato dall'NSX Manager, un'appliance virtuale che funge da cervello centrale del sistema. Tutte le configurazioni, dalla definizione delle reti logiche, alle policy di sicurezza, fino all'onboarding dei transport node, vengono eseguite tramite NSX Manager, che espone un'interfaccia grafica web e un'API RESTful per integrazioni automatizzate.
Un aspetto chiave è che NSX Manager è distribuito tipicamente come cluster di tre nodi per garantire alta disponibilità e scalabilità. Ogni nodo NSX Manager esegue al suo interno tre ruoli software: Policy, Manager e Controller. I primi due ruoli (policy e manager) costituiscono il management plane vero e proprio, mentre il ruolo di controller fornisce il Central Control Plane (CCP), ovvero la componente centralizzata del piano di controllo. Grazie a questa architettura, ogni nodo del cluster NSX Manager è in grado di svolgere tutte le funzioni principali (policy, management e control), e il cluster nel suo insieme mantiene una vista consistente dello stato desiderato tramite un database distribuito che replica i dati di configurazione su tutti i nodi.
Dal punto di vista pratico, ciò significa che anche in caso di perdita di un nodo manager, gli altri possono proseguire le operazioni senza interruzioni, avendo accesso alle stesse informazioni di stato desiderato della rete. Il management plane NSX non è quindi un singolo punto di failure, ed è progettato per resistere a guasti hardware o aggiornamenti mantenendo l'integrità delle configurazioni.
Control Plane centralizzato e locale
Il Control Plane in NSX si occupa di calcolare lo stato di runtime della rete virtuale basandosi sulle configurazioni desiderate impostate nel management plane, e di distribuire queste informazioni ai componenti del data plane. In NSX vi è una distinzione tra Control Plane centralizzato (CCP) e Control Plane locale (LCP):
Il CCP (Central Control Plane) risiede all'interno del cluster di NSX Manager (ruolo di NSX Controller attivo su ciascun nodo manager) e ha la visione globale dell'infrastruttura virtuale. Esso è responsabile di computare lo stato dinamico (ad esempio, tabelle di forwarding, informazioni di topology logica, mapping degli end-point) sulla base della configurazione fornitagli dal management plane. Inoltre, il CCP aggrega le informazioni provenienti dal data plane (ad esempio stati dei tunnel, utilizzo link) per poter prendere decisioni di ricalcolo quando necessario. Un singolo CCP è suddiviso internamente in controller shard, ovvero istanze che si spartiscono la gestione dei vari segmenti della rete virtuale: tipicamente, con un cluster di tre manager, vi sono tre controller che suddividono i carichi (ad es. ciascun transport node viene assegnato ad uno dei controller per le sue configurazioni L2/L3 e regole firewall). Questo meccanismo di sharding garantisce sia la scalabilità (distribuendo il lavoro su più nodi controller) che la resilienza, poiché in caso di failure di un controller il carico viene ricalcolato e redistribuito automaticamente sugli altri nodi senza interrompere il traffico.
L'LCP (Local Control Plane) risiede localmente su ciascun transport node (ad esempio su ogni host ESXi preparato con NSX o su ogni appliance Edge). L' LCP ha il compito di ricevere dal CCP le porzioni di stato di rete rilevanti per quel nodo e applicarle al proprio data plane locale. Inoltre, l'LCP monitora lo stato del nodo (es. link fisici, tunnel verso altri host) e notifica il CCP in caso di cambiamenti significativi. In questo senso, il control plane locale coopera con quello centralizzato: il CCP propaga le informazioni ai nodi e l'LCP fornisce feedback dal nodo al controller centrale, mantenendo il sistema sincronizzato. Infine, l'LCP provvede a istruire gli elementi di forwarding locali (vSwitch, schede NIC virtuali, ecc.) inserendo le regole e tabelle di flusso appropriate.
In sintesi, il Control Plane di NSX è distribuito: la logica centrale (CCP) calcola e orchestra, mentre ogni nodo esegue una parte di controllo locale per reagire velocemente agli eventi del proprio host. Questa architettura distribuita consente alla rete virtuale di adattarsi rapidamente a cambi di stato (es. una VM che migra, un link che cade) e di continuare a inoltrare traffico anche se la connettività con il controller centrale viene temporaneamente meno (il data plane infatti può operare in maniera stateless basandosi sulle ultime regole ricevute, finché non riceve aggiornamenti).
Data Plane e nodi di trasporto
Il Data Plane rappresenta la parte di NSX che effettivamente inoltra i pacchetti di rete e applica le policy di sicurezza sui flussi di traffico. È costituito dai Transport Nodes, ossia gli endpoint dell'infrastruttura NSX che possono essere di vari tipi:
Host hypervisor (nodi di trasporto su ESXi, e anche su KVM nelle implementazioni multihypervisor): ogni host che partecipa a NSX esegue un virtual switch (es. N-VDS o VDS con moduli NSX) che implementa le funzioni di switching, routing distribuito e firewall direttamente nel kernel dell'hypervisor, agendo come piano di inoltro per il traffico delle VM o dei container su quell'host.
Edge Node: appliance virtuali (o bare-metal) che fungono da gateway e servizio edge, fornendo funzionalità come routing centralizzato, NAT, VPN e bilanciamento di carico. Gli Edge sono anch'essi transport node e partecipano al data plane, tipicamente raggruppati in cluster per alta disponibilità.
Bare-metal server (con NSX agent): in alcuni casi, server fisici Linux/Windows o workload containerizzati su bare-metal possono essere integrati come transport node, ad esempio tramite un NSX agent o tramite l'uso di NSX Service-Defined Firewall per estendere la policy a workload non virtualizzati.
Il data plane NSX funziona con un modello distribuito scale-out: ogni nodo di trasporto contribuisce alla capacità di inoltro complessiva e le funzioni di rete (es. switch logici, router distribuiti, firewall distribuito) sono implementate in modo federato su tutti gli host coinvolti. I pacchetti vengono instradati e filtrati direttamente all'origine (sul primo host che li riceve) secondo le tabelle di forwarding e le regole di sicurezza che il control plane ha popolato in quel nodo. Questo approccio elimina colli di bottiglia centralizzati, riduce la latenza (ad es. il traffico tra due VM sullo stesso host non esce mai dall'host) e permette di scalare orizzontalmente aggiungendo nuovi host. Il data plane, oltre a inoltrare traffico, si occupa di mantenere aggiornato il control plane riguardo allo stato della rete: ad esempio, segnala cambi di topologia (come l'attivazione di un nuovo tunnel tra host, o la caduta di un collegamento) affinché il controller centrale possa reagire. È importante notare che le operazioni di forwarding nel data plane sono stateless: ogni decisione di inoltro o filtro è presa consultando le strutture dati (table di flusso, liste di controllo, ecc.) già configurate; questo significa che, una volta impostate le regole, il data plane non necessita di interrogare costantemente il control plane per ogni pacchetto, ma opera in autonomia finché la policy rimane invariata.
Canali di comunicazione (Appliance Proxy Hub e NSX-RPC)
Per far cooperare efficacemente i tre piani (management, control, data), NSX utilizza canali di comunicazione dedicati e sicuri. Il componente centrale in questo meccanismo è l'Appliance Proxy Hub (APH), un servizio eseguito su ogni nodo NSX Manager che gestisce la comunicazione con i transport node. L'APH instaura canali basati su un protocollo proprietario (NSX-RPC) attraverso due porte TCP principali:
Porta 1234: utilizzata per le comunicazioni tra il management plane (NSX Manager) e i nodi di trasporto. Ad esempio, quando si prepara un nuovo host ESXi come transport node, l'NSX Manager tramite APH invia i pacchetti di controllo necessari (installa i componenti, verifica lo stato, ecc.) su questo canale.
Porta 1235: utilizzata per le comunicazioni tra il central control plane (NSX Controller che gira nei manager) e i transport node (LCP). Su questo canale viaggiano le istruzioni di controllo runtime, come l'aggiornamento delle tabelle di flusso su un host o la propagazione di informazioni di stato dal host al controller centrale.
Entrambi i canali sono cifrati e progettati per essere robusti e a bassa latenza, assicurando che configurazioni e aggiornamenti di stato possano propagarsi rapidamente e in modo affidabile nell'infrastruttura. In sintesi, l'APH funge da hub di messaggistica all'interno di NSX, tenendo separati ma coordinati i flussi di comunicazione tra management plane e data plane, e tra control plane e data plane. Questo design a canali separati consente, ad esempio, di non sovraccaricare un singolo endpoint di comunicazione: le attività amministrative (deploy di nuovi componenti, raccolta statistiche, ecc.) viaggiano su una porta dedicata (1234), mentre le attività di controllo del traffico (es. programmazione delle rotte e delle regole firewall runtime) viaggiano su un'altra (1235).
NSX Manager Cluster e Alta Disponibilità
Come accennato, NSX Manager viene tipicamente creato in una configurazione a cluster di tre nodi. Questo cluster costituisce il cuore del management plane NSX on-premises e incorpora anche il control plane centralizzato (CCP). Vediamo più in dettaglio come è strutturato e come assicura alta disponibilità e accesso ai servizi (API/UI) tramite Virtual IP o Load Balancer.
Cluster a tre nodi e database distribuito
Un cluster NSX Manager è formato da tre appliance NSX Manager identiche, ognuna con i ruoli policy, manager e controller attivi. Il motivo per scegliere tre nodi risiede nell'ottenere tolleranza ai guasti (il cluster può continuare a funzionare anche se un nodo cade) e nel garantire prestazioni sufficienti distribuendo il carico di lavoro (ad esempio, in ambienti molto grandi, le operazioni di calcolo del control plane possono essere ripartite su tre controller shard). Tutti e tre i manager partecipano ad un cluster peering in cui uno dei nodi viene eletto leader e gli altri fungono da followers sincronizzati.
Il cluster condivide un database distribuito (basato su CorfuDB) per mantenere lo stato persistente delle configurazioni e dello stato desiderato del sistema. Ogni volta che una modifica di configurazione viene effettuata (ad esempio la creazione di una nuova rete logica o una regola firewall), questa viene registrata nel database distribuito, garantendo che tutti i nodi del cluster abbiano una vista consistente e aggiornata delle informazioni. Questo meccanismo di replicazione è cruciale: se un nodo manager non è disponibile, un altro nodo ha già in locale tutti i dati necessari per proseguire le operazioni. L'uso di un database distribuito e di un algoritmo di consenso per l'elezione del leader assicura inoltre che non vi siano conflitti di scrittura e che in ogni momento uno solo dei nodi agisca da punto di coordinamento per le nuove modifiche (il leader appunto).
Per ambienti di dimensioni differenti, VMware offre appliance NSX Manager di varie taglie (small, medium, large, x-large) per adattarsi al numero di nodi gestiti e al throughput richiesto, ma la regola del cluster a tre nodi rimane best practice per la produzione. In situazioni di laboratorio o test è possibile vedere anche un singolo nodo manager (senza HA), ma ciò ovviamente rappresenta un single point of failure.
Modalità Virtual IP vs Load Balancer
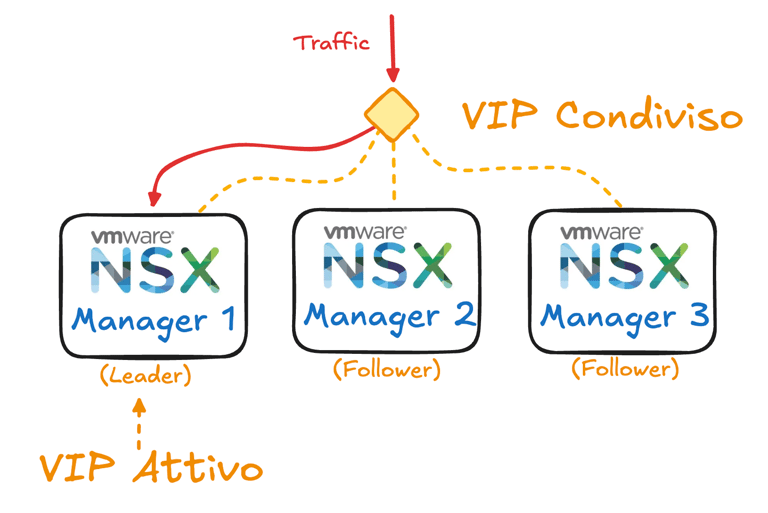
Per consentire agli amministratori e ai sistemi esterni di connettersi al cluster NSX Manager in modo trasparente, esistono due modalità di accesso ad alta disponibilità: tramite Virtual IP (VIP) oppure tramite Load Balancer esterno. Entrambi gli approcci mirano a presentare un singolo endpoint logico (IP virtuale) per l'API e l'interfaccia UI di NSX, evitando che ci si debba collegare a un nodo specifico che potrebbe non essere disponibile.
Cluster con Virtual IP: in questa modalità, ai tre manager viene assegnato un indirizzo IP virtuale condiviso (sul medesimo subnet) che viene fatto puntare dinamicamente al nodo leader corrente. Solo il leader del cluster risponde dunque alle richieste API/UI inviate al VIP, mentre gli altri nodi restano passivi in attesa. In caso di fault del leader, il cluster elegge un nuovo leader e lo stesso VIP viene spostato su quel nodo, garantendo la continuità di accesso. È importante notare che con il VIP non vi è bilanciamento di carico tra i manager: tutto il traffico API/UI va sempre al leader. Inoltre, il traffico che proviene dai transport node (ad esempio gli agent locali che comunicano con il manager) non utilizza il VIP, bensì raggiunge direttamente l'IP management di ciascun nodo come designato (solitamente ogni transport node è “affezionato” al nodo manager leader o a uno specifico controller shard per le comunicazioni di controllo).
Cluster con Load Balancer: in questa modalità, si pone un servizio di bilanciamento (ad esempio un dispositivo NSX Edge con servizio LB, o un altro load balancer fisico/virtuale) davanti ai tre manager. Il load balancer esporrà un virtual server con IP virtuale e distribuirà il traffico in ingresso tra tutti e tre i nodi in modo attivo. Questo significa che tutti i manager possono servire richieste in parallelo, sfruttando pienamente le risorse del cluster. Un vantaggio ulteriore è che i nodi NSX Manager possono trovarsi anche su subnet diverse in questo scenario, poiché il LB si occuperà di instradare correttamente le connessioni. Il load balancing può essere configurato con controlli di health-check sui nodi in modo da escludere automaticamente un manager dal pool in caso di malfunzionamento, garantendo così l'alta affidabilità.
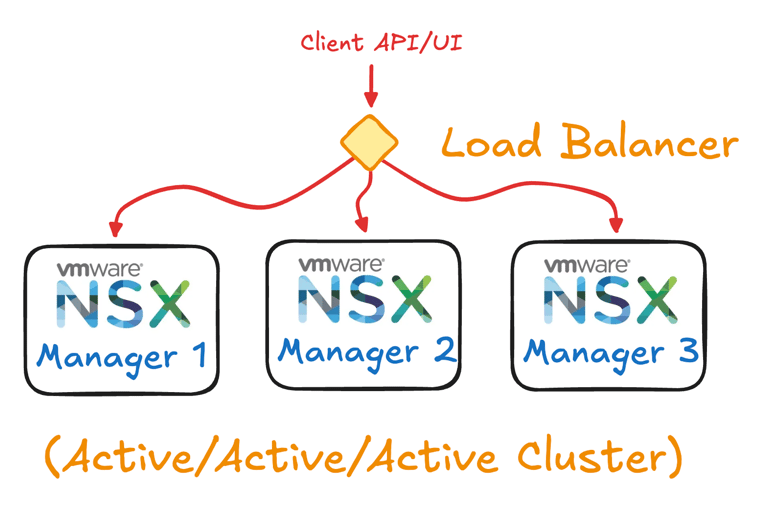
In entrambe le modalità, il risultato è che gli utenti e le applicazioni vedono un singolo NSX Manager logico. La differenza sta principalmente nel bilanciamento del carico e nella topologia: il VIP è semplice da configurare ma concentra il carico sul leader, mentre il LB richiede un componente aggiuntivo ma sfrutta tutte le risorse disponibili. Da notare che il funzionamento interno del cluster rimane lo stesso in entrambi i casi: il database distribuito replica gli stati su tutti i nodi e uno solo è il leader che coordina le modifiche di configurazione. Le scelte VIP vs LB riguardano solo come le chiamate esterne vengono indirizzate al cluster.
Architettura interna di NSX Manager: Policy, Proton, CorfuDB, Reverse Proxy
All'interno di ogni nodo NSX Manager risiede una serie di componenti software interdipendenti che insieme realizzano le funzionalità del management plane e del control plane centralizzato. Comprendere questi componenti e il loro interplay è utile per diagnosticare problemi e ottimizzare le prestazioni. I principali attori interni sono: il Reverse Proxy, il ruolo Policy, il core manager denominato Proton, e il database CorfuDB. Vediamo come interagiscono durante un flusso di lavoro tipico.
Reverse Proxy: è il punto di ingresso a NSX Manager – in pratica un servizio web front-end che riceve tutte le richieste in entrata (sia dall'interfaccia utente Web, sia via API REST). Il reverse proxy autentica e inoltra le chiamate agli appropriati servizi interni di NSX Manager. Esso funge anche da livello di terminazione TLS e da dispatcher, assicurando che le richieste API verso /policy o /api/v1 siano dirette rispettivamente al componente di policy o ad altri servizi manageriali interni.
Policy Role (NSX Policy): è la componente che gestisce le policy di rete e sicurezza a livello alto e costituisce la parte dichiarativa dell'SDN. Quando un utente crea o modifica una configurazione tramite l'UI (che oggi in NSX è principalmente orientata al Policy UI) oppure tramite API policy, sta interagendo con questo servizio. Il ruolo Policy ha il compito di fornire un luogo centralizzato dove definire l'intento di configurazione senza doversi preoccupare dei dettagli di implementazione sottostanti. Ad esempio, un amministratore può definire una regola di sicurezza dicendo "VM di Web tier può parlare con VM di App tier sulla porta 443" e il sistema di policy accetterà questa regola al livello logico. NSX Policy traduce l'intento in configurazioni dettagliate e le applica al ruolo manager all'interno dello NSX Manager. In pratica, il Policy engine valida e memorizza (nel database distribuito) le entità configurate dall'utente e ne enforza l'esistenza creando o aggiornando gli oggetti corrispondenti nel core di NSX Manager (Proton).
Proton (Manager Core): è il core component all'interno di NSX Manager, responsabile delle funzioni manageriali concrete e del calcolo dello stato realizzato. Proton riceve dal componente Policy le configurazioni desiderate (ad esempio la definizione di una nuova subnet logica, o l'associazione di un segmento a un TIER-1 gateway) e si occupa di renderle effettive nel sistema. Gestisce quindi funzionalità chiave come la creazione dei Logical Switch, la configurazione dei Logical Router, l'applicazione delle regole di Distributed Firewall, etc.. Si può pensare a Proton come al motore che prende l'input di alto livello (intento) e lo tramuta in operazioni sui componenti di basso livello: ad esempio, crea entry nelle tabelle MAC e IP dei vari nodi, programma le regole firewall sui host tramite il control plane, e così via. Proton è anche il punto di raccolta per le informazioni di runtime: ad esempio, metriche e statistiche sul traffico vengono raccolte e poi esposte via UI/API attraverso Proton.
CorfuDB (Database Distribuito): sia il ruolo Policy che Proton persistono i dati nel database distribuito sottostante, basato su CorfuDB. CorfuDB è un log replication database ad alte prestazioni che garantisce consistenza forte tra i nodi del cluster. Ogni volta che viene creata o aggiornata una configurazione tramite Policy, l'oggetto viene scritto in CorfuDB, rendendolo immediatamente disponibile a tutti i nodi. Allo stesso modo, Proton registra in database lo stato realizzato, gli identificatori degli oggetti creati e le associazioni necessarie. Grazie a CorfuDB, se un nodo manager viene rimpiazzato o un nuovo nodo entra nel cluster, può rapidamente sincronizzarsi leggendo lo stato dal log replicato. Questo database distribuito è fondamentale anche per consentire l'accesso in lettura su qualunque nodo del cluster (specialmente in modalità con load balancer, dove ogni nodo può servire richieste): poiché i dati sono replicati, una query API su un nodo follower può comunque restituire informazioni aggiornate.
Un tipico flusso di lavoro interno può essere descritto così: l'utente (o un sistema automatizzato) invia una richiesta API al cluster NSX (ad esempio per creare una nuova rete logica). La richiesta arriva al Reverse Proxy, che la inoltra al servizio Policy appropriato. Il Policy engine valida la richiesta, la traduce in oggetti di configurazione e li registra su CorfuDB, quindi notifica a Proton che c'è un nuovo stato desiderato da realizzare. Proton elabora questa configurazione, interagendo se necessario con il NSX Controller (CCP) per calcolare lo stato runtime (ad esempio allocare un VNI per l'overlay, determinare quali transport node partecipano, calcolare percorsi ottimali). Proton quindi distribuisce le istruzioni ai vari nodi tramite il control plane (il CCP comunica con gli LCP sui transport node) per concretizzare la rete richiesta. Infine, Proton può iniziare a raccogliere eventuali statistiche (es. conteggio pacchetti su quella rete) tramite i canali di comunicazione e renderle disponibili via API/UI. Il Reverse Proxy assicura che la risposta all'utente venga recapitata una volta completate (o accettate) le operazioni.
Vale la pena sottolineare che il Reverse Proxy non è solo un pass-through, ma può instradare richieste a diversi servizi interni (ad esempio c'è un servizio specifico per l'autenticazione, uno per l'inventario, ecc.). Tuttavia, dal punto di vista concettuale, i ruoli critici per l'architettura NSX Manager sono i tre descritti: Policy (piano di management dichiarativo), Proton (manager operativo e control plane centrale) e il datastore distribuito che li collega. Questa suddivisione interna riflette l'evoluzione di NSX verso un approccio declarative intent-based: l'utente specifica cosa vuole, il sistema (Proton/Controller) decide come realizzarlo in rete.
Esempi di utilizzo pratico di NSX
Per comprendere il valore di un'architettura come quella descritta, è utile esaminare alcuni casi d'uso pratici abilitati da VMware NSX in ambienti on-premises. Di seguito analizziamo tre scenari chiave – microsegmentazione, automazione della rete e sicurezza distribuita – che beneficiano in modo diretto delle funzionalità offerte da NSX.
Microsegmentazione: uno dei casi d'uso più rivoluzionari portati da NSX è la microsegmentazione, ovvero la capacità di implementare politiche di sicurezza a grana fine all'interno del data center. Tradizionalmente, i firewall segmentavano il traffico solo tra zone di rete (Nord-Sud), lasciando il traffico East-West (tra server nello stesso segmento) poco controllato. Con NSX, grazie al Distributed Firewall (DFW) integrato in ogni host, è possibile applicare regole di firewalling L2-L4 su ogni singola interfaccia virtuale delle VM. Questo significa che ogni macchina virtuale può essere isolata dalle altre anche se risiede sulla stessa rete IP, secondo policy che definiscono con precisione chi può parlare con chi e su quali porte. Ad esempio, si può creare una policy che impedisce a qualunque VM del tier Web di iniziare comunicazioni verso VM del tier Database, salvo quelle esplicitamente permesse, anche se sono tutte sulla stessa VLAN. La microsegmentazione riduce drasticamente la superficie di attacco interna: in caso di compromissione di una VM, l'intruso non può facilmente propagarsi lateralmente perché ogni connessione viene filtrata secondo le regole zero-trust definite. Implementare queste regole a livello distribuito sarebbe ingestibile manualmente, ma NSX consente di farlo centralmente: l'amministratore definisce gruppi di sicurezza e policy a alto livello (es. "Web tier può solo parlare con App tier sulla 443"), e il sistema provvede a distribuirle in modo consistente su tutti gli host interessati. Questo caso d'uso è divenuto quasi sinonimo di NSX, poiché risolve un annoso problema di sicurezza dentro al data center senza richiedere hardware aggiuntivo, sfruttando la virtualizzazione esistente.
Automazione della rete: un altro beneficio fondamentale di NSX è la possibilità di automatizzare completamente il provisioning e la gestione della rete via software. In un ambiente tradizionale, configurare una nuova rete o apportare modifiche (VLAN, subnet, routing, ACL, ecc.) richiede interventi manuali su più dispositivi fisici, con tempi lunghi e alto rischio di errore. Con NSX, l'intera rete è definita a livello software e esposta via API: ciò significa che possiamo integrare NSX con tool di automazione e orchestrazione (come vRealize Automation, Terraform, Ansible, ecc.) per creare on-demand reti, switch virtuali, firewall e bilanciatori, il tutto in pochi secondi e in maniera ripetibile. Ad esempio, immaginate un ambiente di sviluppo in cui per ogni nuova applicazione da testare si debba creare un segmento isolato con 2-3 VM e relative regole firewall: con NSX questo può essere codificato in uno script o blueprint che, via API, instanzia il networking necessario (segmento logico, connesso magari a un router logico per l'uscita, con regole DFW preconfigurate) senza intervento manuale. Quando l'ambiente non serve più, le risorse virtuali di rete vengono eliminate con la stessa rapidità. Questa agilità operativa trasforma il networking in un servizio on-demand, allineandolo alla velocità delle VM e dei container. Inoltre, l'automazione riduce gli errori di configurazione e garantisce che le policy siano applicate in modo uniforme. Molte organizzazioni adottano NSX proprio per integrarlo nei loro workflow DevOps e di Infrastructure as Code, colmando il gap tra provisioning delle VM e provisioning delle reti ad esse associate.
Sicurezza distribuita: oltre al firewall distribuito per la microsegmentazione, NSX abilita una più ampia gamma di servizi di sicurezza distribuiti nel fabric virtuale. Ad esempio, NSX include funzionalità come IDS/IPS distribuito, che consente di individuare intrusioni o attacchi analizzando il traffico direttamente sugli host prima che entri nella rete; oppure la possibilità di integrare servizi di terze parti (come antivirus, sandboxing, etc.) inserendoli in modo trasparente nelle path del traffico virtuale tramite la feature Service Insertion. Tutto questo segue il principio che la sicurezza non deve più essere centrata solo sul perimetro, ma incastonata in ogni punto dell'infrastruttura. Con NSX, le policy di sicurezza possono seguire le VM ovunque vadano (anche in caso di migrazione VM live vMotion), perché non dipendono dalla posizione fisica ma dall'identità logica degli asset. Un esempio pratico: se una VM viene etichettata nel gruppo "Applicazione Critica", automaticamente erediterà tutte le policy di sicurezza previste per quel gruppo (firewall, monitoraggio IDS, restrizioni di accesso), indipendentemente dall'host o dal subnet IP in cui si trova. In un mondo in cui le minacce possono emergere ovunque, la sicurezza distribuita offerta da NSX crea un modello di difesa molto più granulare e adattivo rispetto al passato.
Conclusione
VMware NSX si conferma una tecnologia centrale per realizzare il concetto di Virtual Cloud Network, fornendo un layer software unificato per networking e security attraverso data center e cloud eterogenei. Abbiamo visto come l'architettura di NSX in ambienti on-premises sia concepita per garantire sia flessibilità che robustezza: la separazione in piani di gestione, controllo e dati permette di scalare e controllare la rete virtuale senza impattare il traffico; il cluster NSX Manager a tre nodi, con ruoli integrati di policy/manager/controller, assicura alta disponibilità e consistenza delle configurazioni su tutti i nodi; i meccanismi interni come il database distribuito (CorfuDB) e i servizi Policy/Proton orchestrano efficacemente l'intento dell'utente traducendolo in stato realizzato; il control plane distribuito (CCP+LCP) ed i canali di comunicazione dedicati (NSX-RPC via APH) garantiscono che ogni modifica sia propagata velocemente e in modo affidabile a tutti i nodi interessati.
Per gli esperti di virtualizzazione, NSX rappresenta uno shift paradigmatico: la rete diventa programmabile, adattabile e sicura by-design. Funzionalità come la microsegmentazione e la sicurezza distribuita consentono livelli di protezione prima impensabili senza complessi apparati fisici, mentre l'automazione network-driven accelera il provisioning e riduce gli errori operativi. Il tutto viene gestito da un'unica piattaforma coerente, integrata con l'ecosistema VMware e aperta all'integrazione con strumenti di terze parti tramite API. In definitiva, VMware NSX realizza una rete virtuale centrata sul software che accompagna l'azienda nell'era del cloud, dove l'agilità e la sicurezza non sono più optional ma requisiti fondamentali. Grazie alla solidità dell'infrastruttura NSX on-premises e alle sue capacità evolute, le organizzazioni possono abbracciare con fiducia architetture ibride e multicloud, sapendo di poter contare su un tessuto di connettività e sicurezza unificato e resiliente.